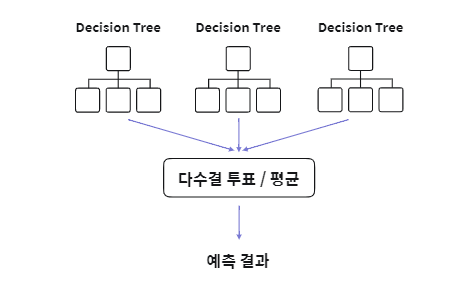
랜덤 포레스트(Random Forest)
- 의사결정 트리 + Bagging 알고리즘
- 부트스트랩 데이터를 생성할 때, 입력 변수에 대해서도 복원 추출
- 데이터 셋에서 Bootstrap을 통해 N개의 훈련 데이터셋을 생성하고, 생성한 N개의 의사결정 나무들을 학습함
- 학습된 트리들의 예측 결과값의 평균 또는 다수결 투표 방식 이용하여 결합
- 변수의 중요성을 파악할 수 있음
- 변수 일부를 사용하기 때문에 과적합을 방지할 수 있음
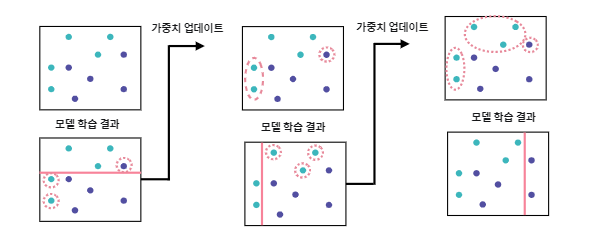
Ada Boost(Adaptive Boosting:적응 부스팅)
- 이전 학습 과정에서 오분류한 데이터를 다음 학습 과정에서는 잘 분류할 수 있도록 하여 Weak Learner를 Strong Learner로 수정하는 Boosting 알고리즘
- 이전 모델이 오분류한 데이터의 가중치를 바꾸어가며 다음 학습에서는 해당 데이터에 더 집중할 수 있도록 함
- 오분류 데이터에 대해 모델을 적합할 수 있음
- 과적합 발생 가능성이 높으며, 계산 과정에 있어 병렬 수행이 불가능함.
Gradient Boosting(Gradient Descent + Boosting)
- Ada Boost와 동일한 원리지만 차이점은 가중치 업데이트 과정에서 Gradient Descent를 사용한다는 것
가중치 업데이트: 오차는 손실함수로 표현되고, 이 손실함수를 최적화 하는 데 있어 Gradient Descent를 사용함
- 계산량이 많이 필요하나 높은 성능을 도출하기 떄문에 유용하게 활용됨
- 효율적인 연산이 가능하도록 파이썬 라이브러리 정의
- Gradient Boosting을 응용한 다양한 모델들이 개발됨
XGBoost(eXtreme Gradient Boosting)
- 2014년 등장, 일반 Gradient Boosting 모델과 작동 원리는 동일하나, 과적합(Overfitting)을 방지하기 위해 정규화된 모델 사용
- 불순도(impurity)를 감소하는 방향만 강조되는 기존 트리에서 정규화(Regularization)을 추가하여 모델의 복잡성도 고려
- 분산/병렬 처리를 통해 실행 속도를 보완하며, 대부분의 문제에서 양호한 예측 성능을 보임
- 다양한 하이퍼 파라미터 지원 및 조절을 통해 과적합 방지에 효율적
LGBM(Light Gradient Boosting Model)
- XGBoost에 비해 더 가볍고 빠른 실행 속도를 가진 모델
- 범주형 변수 처리 지원 기능 추가
범주형 변수: 배타적인 범주 변수
- 대용량 데이터에서의 실행 속도 개선
- 기존 XGBoost 대비 적은 메모리 사용
- 적은 수의 데이터 적용 시 과적합 문제 발생 가능성
CatBoost(Categorical + Boosting model)
- 2017년 등장, 범주형 변수를 위한 다양한 기능을 지원하는 부스팅 모델
- Category 변수에 대한 전처리 문제 해결
- 범주형 변수를 자동으로 처리해 타입 변환 오류를 피할 수 있음
- 범주형과 수치형 변수들의 combination을 처리
- 변수 간의 상관관계를 계산함과 동시에 속도 개선, Multiple-category 데이터를 다룰 때 유용
출처: 앨리스 교육
랜덤 포레스트(Random Forest)
- 의사결정 트리 + Bagging 알고리즘
- 부트스트랩 데이터를 생성할 때, 입력 변수에 대해서도 복원 추출
- 데이터 셋에서 Bootstrap을 통해 N개의 훈련 데이터셋을 생성하고, 생성한 N개의 의사결정 나무들을 학습함
- 학습된 트리들의 예측 결과값의 평균 또는 다수결 투표 방식 이용하여 결합
- 변수의 중요성을 파악할 수 있음
- 변수 일부를 사용하기 때문에 과적합을 방지할 수 있음
Ada Boost(Adaptive Boosting:적응 부스팅)
- 이전 학습 과정에서 오분류한 데이터를 다음 학습 과정에서는 잘 분류할 수 있도록 하여 Weak Learner를 Strong Learner로 수정하는 Boosting 알고리즘
- 이전 모델이 오분류한 데이터의 가중치를 바꾸어가며 다음 학습에서는 해당 데이터에 더 집중할 수 있도록 함
- 오분류 데이터에 대해 모델을 적합할 수 있음
- 과적합 발생 가능성이 높으며, 계산 과정에 있어 병렬 수행이 불가능함.
Gradient Boosting(Gradient Descent + Boosting)
- Ada Boost와 동일한 원리지만 차이점은 가중치 업데이트 과정에서 Gradient Descent를 사용한다는 것
가중치 업데이트: 오차는 손실함수로 표현되고, 이 손실함수를 최적화 하는 데 있어 Gradient Descent를 사용함
- 계산량이 많이 필요하나 높은 성능을 도출하기 떄문에 유용하게 활용됨
- 효율적인 연산이 가능하도록 파이썬 라이브러리 정의
- Gradient Boosting을 응용한 다양한 모델들이 개발됨
XGBoost(eXtreme Gradient Boosting)
- 2014년 등장, 일반 Gradient Boosting 모델과 작동 원리는 동일하나, 과적합(Overfitting)을 방지하기 위해 정규화된 모델 사용
- 불순도(impurity)를 감소하는 방향만 강조되는 기존 트리에서 정규화(Regularization)을 추가하여 모델의 복잡성도 고려
- 분산/병렬 처리를 통해 실행 속도를 보완하며, 대부분의 문제에서 양호한 예측 성능을 보임
- 다양한 하이퍼 파라미터 지원 및 조절을 통해 과적합 방지에 효율적
LGBM(Light Gradient Boosting Model)
- XGBoost에 비해 더 가볍고 빠른 실행 속도를 가진 모델
- 범주형 변수 처리 지원 기능 추가
범주형 변수: 배타적인 범주 변수
- 대용량 데이터에서의 실행 속도 개선
- 기존 XGBoost 대비 적은 메모리 사용
- 적은 수의 데이터 적용 시 과적합 문제 발생 가능성
CatBoost(Categorical + Boosting model)
- 2017년 등장, 범주형 변수를 위한 다양한 기능을 지원하는 부스팅 모델
- Category 변수에 대한 전처리 문제 해결
- 범주형 변수를 자동으로 처리해 타입 변환 오류를 피할 수 있음
- 범주형과 수치형 변수들의 combination을 처리
- 변수 간의 상관관계를 계산함과 동시에 속도 개선, Multiple-category 데이터를 다룰 때 유용
출처: 앨리스 교육