
이전 직장에서 AWS Glue와 Athena를 이용해 ETL 파이프라인을 구성한 경험이 있다. AWS 내 있는 기술들이다 보니 사용법도 굉장히 쉽고 편했는데 이번 시간에는 이를 이용해서 MongoDB 데이터 분석 방법을 비교해보자. 최근 애플리케이션에서 발생되는 데이터는 주로 JSON 다큐먼트 형태로 저장된다. 이는 MongoDB와 같은 다큐먼트 지향 데이터베이스의 사용도 같이 늘어나게 한다. MongoDB는 사용해본 경험이 아직 없어서 잘 모르지만 이번 글을 통해 어떻게 데이터를 분석하는지 알아보자.
기술 블로그 출처
AWS Glue와 Amazon Athena를 활용한 MongoDB 데이터 분석 방법 비교하기 | Amazon Web Services
IoT 디바이스 또는 웹/앱 애플리케이션에서 발생되는 데이터는 JSON 다큐먼트 형태로 주로 저장되고 있으며, 이 데이터에 대한 분석 요구가 증대됨에 따라 MongoDB와 같은 다큐먼트 지향 데이터베이
aws.amazon.com
이 게시글은 AWS에서 제공하는 서버리스 분석 서비스 중 Amazon Athena를 사용하여 JSON 다큐먼트 형태의 데이터를 쉽게 분석하는 방법에 대해 소개한다. Amazon Athena는 프로비저닝이나 구성 작업 없이 SQL 또는 Apache Spark를 기반으로 하는 대화형 분석 서비스로, 페타바이트 규모의 데이터를 효과적으로 처리할 수 있다. 최근에 공개된 Athena Provisioned Capacity를 소개하며 다수의 동시 쿼리 실행에 대비해 전용 쿼리 처리 용량을 효과적으로 활용하는 방법을 설명한다.
솔루션 개요
MongoDB 데이터를 Amazon Athena로 조회하는 두가지 방법
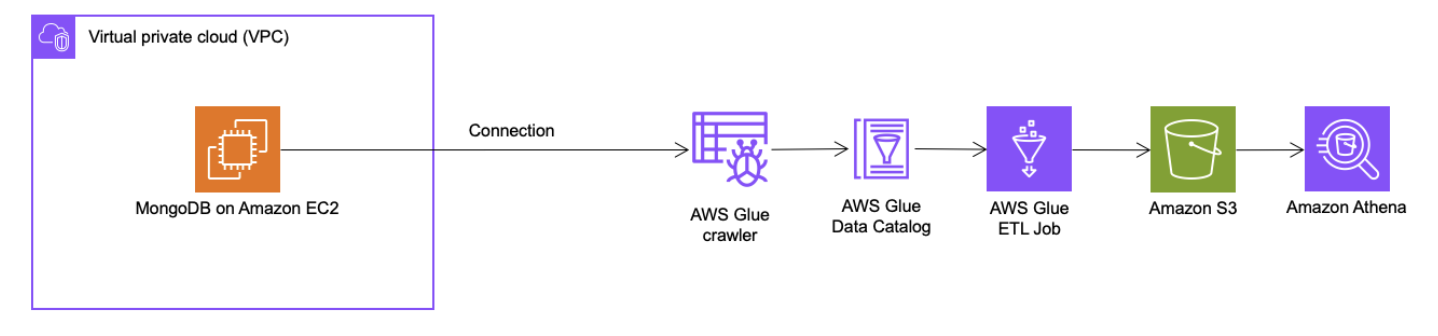
- AWS Glue 크롤러를 실행하고 Amazon Athena에서 쿼리하는 방법
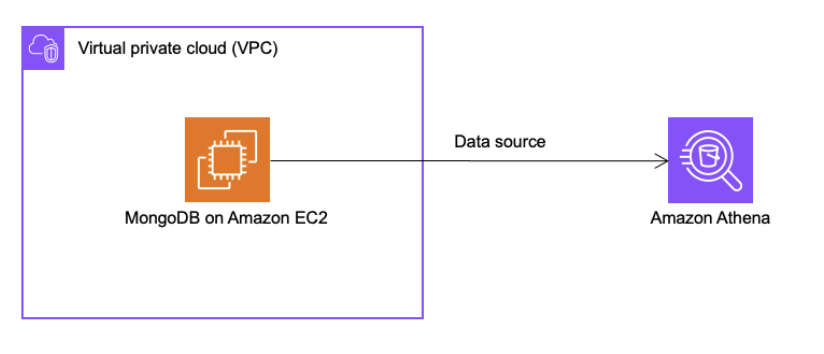
- Amazon Athena에서 데이터 소스를 설정하고 Athena Federated Query를 통해 직접 쿼리하는 방법
방법1은 AWS Glue를 사용하여 데이터를 저장하는 데 더 많은 프로세스와 리소스가 필요하지만, 훨씬 유연하고 분석 옵션을 제공할 수 있다. 반면에 방법2는 더 간단하고 빠르게 데이터를 분석할 수 있지만, 데이터 레이크에 저장하지 않기 때문에 유연하지 않아 활용면에서 제약이 있을 수 있다.
단계 요약
- [방법1] AWS Glue crawler 실행 후, Amazon Athena에서 쿼리
- MongoDB on EC2 생성
- Dummy Data 생성
- AWS Glue Connection 및 crawler 설정
- AWS Glue ETL Job 생성 및 실행
- Amazon Athena에서 데이터 조회
- [방법2] Amazon Athena에서 Data source를 설정하고 Athena Federated Query를 통해 직접 쿼리
- Amazon Athena에서 Data source 생성
- Amazon Athena Federated Query 실행
결론
데이터 분석 패턴에 따라 알맞은 방법을 선택하여 비즈니스 요구사항에 맞게 AWS 분석 서비스를 활용할 수 있다.
| 항목 | AWS Glue ETL을 통한 분석 | Amazon Athena Federated Query를 통한 분석 |
| 데이터 조회 시간 | ETL에 따른 시간 지연 | 즉시 조회 |
| 데이터 저장 | S3에 데이터 저장 | 별도 데이터 저장 불필요 |
| 소요 비용 | Glue 비용, S3 저장 비용, Athena 스캔 비용 | Athena 스캔 비용, Lambda 호출 비용 |
| 분석 패턴 | 배치 분석 | 실시간 분석 |
| 활용 사례 | 소스 데이터의 원본 저장이 필요한 경우 소스 테이터의 복잡한 변환이 필요한 경우 |
소스 데이터의 변환없이 다른 데이터와 즉시 조인이 필요한 경우 |
후기
MongoDB와 같은 다큐먼트 지향 데이터베이스의 활용이 증가하고 있다. 다양한 형태의 데이터를 다루기 위해 NoSQL 데이터베이스를 어떻게 활용할 수 있는지 알 수 있었고 Amazon Athena를 사용해 애드혹 쿼리로 데이터를 분석할 수 있다는 점도 흥미로웠다.
이전 직장에서 AWS Glue와 Athena를 이용해 ETL 파이프라인을 구성한 경험이 있다. AWS 내 있는 기술들이다 보니 사용법도 굉장히 쉽고 편했는데 이번 시간에는 이를 이용해서 MongoDB 데이터 분석 방법을 비교해보자. 최근 애플리케이션에서 발생되는 데이터는 주로 JSON 다큐먼트 형태로 저장된다. 이는 MongoDB와 같은 다큐먼트 지향 데이터베이스의 사용도 같이 늘어나게 한다. MongoDB는 사용해본 경험이 아직 없어서 잘 모르지만 이번 글을 통해 어떻게 데이터를 분석하는지 알아보자.
기술 블로그 출처
AWS Glue와 Amazon Athena를 활용한 MongoDB 데이터 분석 방법 비교하기 | Amazon Web Services
IoT 디바이스 또는 웹/앱 애플리케이션에서 발생되는 데이터는 JSON 다큐먼트 형태로 주로 저장되고 있으며, 이 데이터에 대한 분석 요구가 증대됨에 따라 MongoDB와 같은 다큐먼트 지향 데이터베이
aws.amazon.com
이 게시글은 AWS에서 제공하는 서버리스 분석 서비스 중 Amazon Athena를 사용하여 JSON 다큐먼트 형태의 데이터를 쉽게 분석하는 방법에 대해 소개한다. Amazon Athena는 프로비저닝이나 구성 작업 없이 SQL 또는 Apache Spark를 기반으로 하는 대화형 분석 서비스로, 페타바이트 규모의 데이터를 효과적으로 처리할 수 있다. 최근에 공개된 Athena Provisioned Capacity를 소개하며 다수의 동시 쿼리 실행에 대비해 전용 쿼리 처리 용량을 효과적으로 활용하는 방법을 설명한다.
솔루션 개요
MongoDB 데이터를 Amazon Athena로 조회하는 두가지 방법
- AWS Glue 크롤러를 실행하고 Amazon Athena에서 쿼리하는 방법
- Amazon Athena에서 데이터 소스를 설정하고 Athena Federated Query를 통해 직접 쿼리하는 방법
방법1은 AWS Glue를 사용하여 데이터를 저장하는 데 더 많은 프로세스와 리소스가 필요하지만, 훨씬 유연하고 분석 옵션을 제공할 수 있다. 반면에 방법2는 더 간단하고 빠르게 데이터를 분석할 수 있지만, 데이터 레이크에 저장하지 않기 때문에 유연하지 않아 활용면에서 제약이 있을 수 있다.
단계 요약
- [방법1] AWS Glue crawler 실행 후, Amazon Athena에서 쿼리
- MongoDB on EC2 생성
- Dummy Data 생성
- AWS Glue Connection 및 crawler 설정
- AWS Glue ETL Job 생성 및 실행
- Amazon Athena에서 데이터 조회
- [방법2] Amazon Athena에서 Data source를 설정하고 Athena Federated Query를 통해 직접 쿼리
- Amazon Athena에서 Data source 생성
- Amazon Athena Federated Query 실행
결론
데이터 분석 패턴에 따라 알맞은 방법을 선택하여 비즈니스 요구사항에 맞게 AWS 분석 서비스를 활용할 수 있다.
| 항목 | AWS Glue ETL을 통한 분석 | Amazon Athena Federated Query를 통한 분석 |
| 데이터 조회 시간 | ETL에 따른 시간 지연 | 즉시 조회 |
| 데이터 저장 | S3에 데이터 저장 | 별도 데이터 저장 불필요 |
| 소요 비용 | Glue 비용, S3 저장 비용, Athena 스캔 비용 | Athena 스캔 비용, Lambda 호출 비용 |
| 분석 패턴 | 배치 분석 | 실시간 분석 |
| 활용 사례 | 소스 데이터의 원본 저장이 필요한 경우 소스 테이터의 복잡한 변환이 필요한 경우 |
소스 데이터의 변환없이 다른 데이터와 즉시 조인이 필요한 경우 |
후기
MongoDB와 같은 다큐먼트 지향 데이터베이스의 활용이 증가하고 있다. 다양한 형태의 데이터를 다루기 위해 NoSQL 데이터베이스를 어떻게 활용할 수 있는지 알 수 있었고 Amazon Athena를 사용해 애드혹 쿼리로 데이터를 분석할 수 있다는 점도 흥미로웠다.